Key Concepts
- buckets 每个stat都有各自的
bucket,无需事先定义 - values 每个stat都会有一个value
Line Protocol
1 | <metricname>:<value>|<type> |
1 | echo "foo:1|c" | nc -u -w0 127.0.0.1 8125 |
Workflow
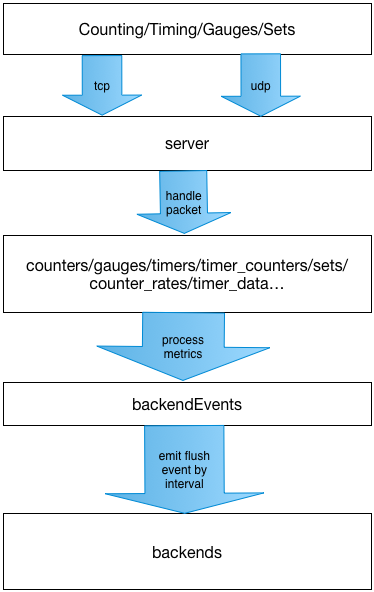
Project Struct
1 | ├── CONTRIBUTING.md |
stats.js
应用启动的入口文件,主要:
- 声明一些全局存储变量
- 声明一些根据config启动server的函数
- 根据process.args[2]即配置文件路径启动应用
具体的代码的逻辑大致如下:
- config.configFile(configPath:String),加载配置
- process_mgmt.init(config:Object),设置进程相关的一些基本参数
- 根据config.prefixStats(String:’statsd’)来设置一些内置metric的前缀
- 初始化counter内bad_lines_seen、packets_received、metrics_received为0
- 通过config.keyNameSanitize判断是否需要转义metric key
- 声明
handlePacket(msg:Buffer,rinfo:Object),主要作用是接受报文,根据line protocol解析,然后将结果写入一开始申明的全局变量 - 根据config.servers的配置,从servers目录中加载并启动server,server监听的回调函数就是上一步中声明的handlePacket
- mgmt_server.start(conifg:Object,on_data_callback:Functioin,on_error_callback),启动一个tcp的mangement的server
- 设置percentThreshold,默认[90]
- 设置flushInterval,默认10s
- 根据config.backends设置后端的server,默认为
backends/graphite。注意:如果我们需要测试,可以设置为backends/console - 通过在flushMetrics函数中使用递归调用setTimeout实现flush timer。flushMetrics的大致逻辑内部逻辑为:
- 先构造metrics_hash对象
- 在backendEvents:EventEmiter中注册flush事件监听,如果config设置了相关的delete配置,则删除相关key,否则置为0或者空数组
- 通过process_metrics对构造的metrics_hash对象根据配置做一些加工计算处理,结束之后触发的backendEvents的flush事件
- 再次注册setTimeout,进行下一次flush
lib/process_metrics.js
主要作用是对stats.js中flushMetrics函数中传入的metric_hash做计算加工,并将结果返回出去
具体代码逻辑如下:
- 声明基本的局部存储变量
- 遍历counter,将将每秒的结果计算至counter_rates中
- 遍历timers,每个timer对应的是数组,形如
bar: [200, 198, 199]这样。因为timer表示的内容比较丰富,所以计算会多一些,timers中的计算结果最终会计算至timer_data中。比如timers: { bar: [ 100, 200 ] },至少会计算出
1 | std: 50, |
然后根据pctThreshold参数,计算出各个不同分位的指标,像这样
1 | count_$pct |
值得注意的是,关于$pct的相关的指标计算是将排序后,计算落在$pct内的点的计算
做个简单的测试
1 | echo "foo:1|c\nbar:1|ms\nbar:2|ms\nbar:3|ms\nbar:4|ms\nbar:5|ms\n" | nc -u -w0 127.0.0.1 8125 |
console的backend显示如下:
1 | { counters: |
backends/console.js
Flush stats to graphite
每个backend中的代码均需要实现init方法,在stats.js中通过loadBackend函数调用。init方法中传入的参数有:
1. startup_time, 启动时间
2. config,
3. backendEvents,
4. l,日志对象
init函数按照约定都需要同步返回true
比如backends/console.js,init中初始化了ConsoleBackend的一个实例,在构造函数中注册了对参数backendEvents的flush和flush事件
backends/graphite.js
Metric
对发送至graphite的指标数据做了封装
1 | constructor(key:String,val:Number,ts:Timestamp) |
Stats
指标数据的集合,提供了add方法和toText和toPickle这两个序列化实现
init
- 设置默认host、port、protocol
- 设置不同指标的默认的前缀和后缀
flush_stats
- 分别遍历metrics数据中的counters、timer_data、gauges、sets,统一添加至Stats的类实例中,方便后续统一做序列化处理
- 在添加时stats实例中,会根据统一的前缀和后缀和命名空间做一些指标名称的处理
post_stats
- 根据config中的host、port建立socket连接
- 连接成功时,在stats实例中添加统计信息,根据protocol选择序列化方式并写入socket
- 写入成功之后更新graphiteStats的统计信息,失败也是一样
总结:
- 代码很简单,由于是一个定时的flush的机制,将很多状态直接存储在对象中
backend/*的解耦了process metrics和flush backend,backend/console在开发时用起来很方便- 作为一个
daemon process,通过mangent server提供简单tcp接口来反馈当前的统计信息。 - 指标的量很大,所以在协议设计方面尽可能简单,并且对于不论是
handlePacket和flush backend时,都尽可能使用了batch - 在metrics的架构中,通常作为缓冲层存在。将大量的point的请求在时间维度做聚合,也是
batch思想的体现